Wenn man eine Maschine und 300$ hat, dann lässt man die Maschine auch was lernen, denn man kann es sich ja leisten. Dieser Blogeintrag zeigt in aller notwendigen Kürze, wie ich ein mlr3 Modell aus auf Google Cloud laufen lasse.
Autor:in
Manuel Reif
Veröffentlichungsdatum
8. Februar 2025
mlr3 ist ein Package, das mich phasenweise leiden lässt. Jeder, der das schon einmal gesehen hat, will es nicht noch einmal erleben. Dennoch löst mlr3 einige Probleme und, wie jedes gute Package, löst es mehr Probleme, als es neue schafft. Vielleicht ist es nicht unbedingt etwas für den 08/15-R-Anwender, der gerne einmal ein Machine-Learning-Modell laufen lassen möchte, um zu sehen, wie man sich als Data Scientist fühlt, sondern eher für jemanden, der heute, morgen und vermutlich auch übermorgen unterschiedliche Modelle fitten und vor allem tunen möchte. Denn so cool es auch ist, dass jeder da draußen ein R-Package schreiben kann, so schwierig ist es, sich auf die Logik jedes einzelnen Packages einzulassen. Die Zeit fehlt oft, obwohl man natürlich gerne die neuesten Modelle anwenden will (so wie ich Random Forests ).
mlr3 ist nicht das einzige Package, das dieses Problem zu lösen versucht, aber das einzige, das wir uns hier ansehen. Auf der useR! 2024 stolperte ich mehr oder weniger in einen überfüllten Seminarraum und damit in ein Tutorial zu mlr3. Schicksalhafte Begegnungen, die nun in diesem Blogpost münden. Der stille Held dieser und aller weiteren Stories auf der Google Cloud ist wieder der gute alte Docker Container, der wie ein gutes Elternteil alles mit dabei hat, was notwendig ist, um den Ausflug der R-Files in die Cloud zu ermöglichen.
Der Datensatz
Schlaganfälle sind eine ernste Sache. Um das Risiko eines Schlaganfalls vorhersagen zu können, muss man Daten sammeln. In diesem Datensatz existieren 11 clinical features - quasi die unabhängigen Variablen. Tabelle 1 und Tabelle 2 zeigen getrennt nach Skalenniveau die einzelnen Variablen. Die Variable, die es vorherzusagen gilt, ist stroke – kodiert als 0/1. Die Angabe in der Tabelle ist etwas unintuitiv – sie weist letztlich die Anzahl der Schlaganfälle (1) bzw. deren Anteil an den Gesamtbeobachtungen aus. Was die anderen Variablen im Detail bedeuten, ist nicht unbedingt wichtig. Wir wollen sie bloß verwenden, um stroke möglichst gut zu erklären. Allerdings scheinen die Variablen sinnvoll: Alter (macht alles schlechter), Bluthochdruck, die Frage nach einer bereits bestehenden Herzerkrankung, der BMI oder die Information ob jemand raucht oder nicht etc. wollen wir hier in weiterer Folge auf ihre prognostische Werthaltigkeit prüfen.
Tabelle 2: Beschreibung der kategorialen Variablen
Characteristic
N
N = 5,1101
gender
5,110
Female
2,994 (59%)
Male
2,115 (41%)
Other
1 (<0.1%)
ever_married
5,110
3,353 (66%)
work_type
5,110
children
687 (13%)
Govt_job
657 (13%)
Never_worked
22 (0.4%)
Private
2,925 (57%)
Self-employed
819 (16%)
Residence_type
5,110
Rural
2,514 (49%)
Urban
2,596 (51%)
smoking_status
5,110
formerly smoked
885 (17%)
never smoked
1,892 (37%)
smokes
789 (15%)
Unknown
1,544 (30%)
1 n (%)
Das Package
Um alle Abläufe rund um ein Machine-Learning-Projekt nicht immer selbst implementieren zu müssen, ist es klug, auf ein Package zurückzugreifen, das dem/der User:in die wesentlichsten Schritte schon einmal abnimmt. Sonst findet man sich in der ermüdenden Lage, verschachtelte Schleifen zu schreiben und Funktionen zu definieren, die man eigentlich noch viel allgemeiner formulieren könnte, um sie einfacher wiederverwenden zu können. Aber will man schon so sehr in der Zukunft leben, dass man die gerade aktuelle Funktion so baut, dass sie nicht nur das aktuelle, sondern auch möglichst alle zukünftigen Probleme gleicher oder ähnlicher Art löst? Manchmal will man das. Manchmal will man aber auch nur das aktuelle Problem lösen, ohne schon an morgen denken zu müssen, insbesondere, wenn sich bereits andere Menschen ihren schönen Kopf über solche Funktionen zerbrochen und ein mutmaßlich benutzerfreundliches Funktionskonstrukt geschaffen haben, das uns viel Denkarbeit abnimmt. Man muss nur lernen, mit dem Package umzugehen und sich daran zu gewöhnen. Also, das Package, mit dem hier gearbeitet wird, ist – wie schon angekündigt – mlr3.
Der Plan
Hier der konkrete, geplante Ablauf:
Wähle eine Methode, mit der die Target-Variable (stroke) vorhergesagt werden soll.
Bereite den Datensatz so auf, wie es für die gewählte Methode notwendig ist.
Splitte den Datensatz in Trainings- und Testdatensatz. Der Testdatensatz kann dann verwendet werden, um unterschiedliche Methoden anhand ihrer Prognoseleistung zu vergleichen.
Führe eine wiederholte Cross-Validation (CV) auf dem Trainingsdatensatz durch (z. B. klassische 5-fold-CV). Das bedeutet, der Datensatz wird in fünf Teile geteilt: Auf 4/5 der Daten wird das Modell trainiert und auf dem restlichen 1/5 wird vorhergesagt. Dies wird fünfmal wiederholt.
Fitte auf dem Trainingsdatensatz ein beliebiges Modell (z. B. einen Random Forest) mit einer bestimmten Parameterkonstellation.
Tune die Parameter, um die beste Parameterkombination zu ermitteln!
Am Ende versuchst du, mit dem getunten Modell stroke im Testdatensatz vorherzusagen. Diese Performance gibt uns eine gute Einschätzung, wie gut das Modell in Zukunft performen wird!
Dieser Plan findet bei mir üblicherweise als R-Code seinen Niederschlag. Konkret sieht der Code so aus.
Code: Random Forests mit mlr3
1library(data.table)library(magrittr)library(mlr3)library(mlr3tuning)library(mlr3extralearners)library(mlr3learners)library(mlr3pipelines)library(paradox)library(bbotk)library(mlr3mbo)library(forcats)library(future)2plan(multicore)## Argumente uebernehmen3args <-commandArgs(trailingOnly =TRUE)# defaultsdefault_evals <-20default_duration <-2*60*60n_evals <-ifelse(length(args) >=1, as.integer(args[1]), default_evals)duration <-ifelse(length(args) >=2, as.integer(args[2]), default_duration)cat("\n -------------------------------------------- \n")cat("Tuning Stoppt nach:\n")cat(" Evals:", n_evals, "\n")cat(" Zeit in Sekunden:", duration)cat("\n -------------------------------------------- \n\n")set.seed(42)# einlesen und moddend =fread("healthcare-dataset-stroke-data.csv") %>% .[, bmi :=as.numeric(ifelse(bmi =="N/A", NA_character_, bmi))] %>% .[, id :=as.character(id)] %>%# id muss ein character sein! .[gender !="Other",]#### TASK ####################################################################### es ist etwas kompliziert eine variable den feature status zu entziehen.4task_stroke =as_task_classif(d, target ="stroke")task_stroke$col_roles$feature <-setdiff(task_stroke$col_roles$feature, "id")task_stroke$col_roles$name <-"id"5task_stroke$set_col_roles("stroke", c("target","stratum"))split =partition(task_stroke, ratio =0.8) ### learner --------------------------------------------------------------------6learner_rf =lrn("classif.ranger",predict_type ="prob",respect.unordered.factors ="partition",importance ="permutation",num.trees =5000,id ="rf") # mit id = "rf" kann ich bei ps dann die präambel kuerzer schreiben# rf muss davor geschrieben werden, weil es sonst bei der pipe unklarheiten# bezueglich parameternamen gibt!7param_set =ps(rf.mtry.ratio =p_dbl(0.4, 1),rf.min.node.size =p_int(20, 800) )### resampling -----------------------------------------------------------------8resampling_CV5 =rsmp("cv", folds =5)measure_AUC =msr("classif.auc")### tuner ----------------------------------------------------------------------9tuner_bayes =tnr("mbo")### terminator -----------------------------------------------------------------10terminator2 =trm("combo",list(trm("evals", n_evals = n_evals),trm("run_time", secs = duration) ))### pipeline -------------------------------------------------------------------po_impute_d_uk <-po("imputelearner", learner =lrn("regr.rpart"), param_vals =list(affect_columns =selector_type("numeric") ), id ="imp_d_uk")11pip_rob =pipeline_robustify(task = task_stroke,learner = learner_rf,character_action ="factor!",impute_missings =FALSE) %>>%po_impute_d_uk %>>%po("learner", learner = learner_rf) ### autotune -------------------------------------------------------------------at = AutoTuner$new(learner = pip_rob,resampling = resampling_CV5,measure = measure_AUC,search_space = param_set,terminator = terminator2,tuner = tuner_bayes)at$train(task_stroke, row_ids = split$train)pred_res = at$predict(task_stroke, row_ids = split$test)auc_test = measure_AUC$score(pred_res)full_res =list(at = at, pred_res = pred_res, auc_test = auc_test,split = split)saveRDS(full_res, "output/ranger_only.rds")
1
Wir laden wirklich viele Packages, insbesondere mlr3 und seine Freunde. Im unten stehenden Dockerfile sieht man, welche Packages in Summe installiert werden. Das heißt: Lässt man alles im Docker-Container laufen, wird alles fix und fertig installiert!
2
Wir wollen parallelisieren, sonst dauert es zu lange. Mit dieser Einstellung werden alle vorliegenden Kerne genutzt. Als Argument kann man multicore oder multisession verwenden. multicore funktioniert nur unter Linux, aber Vorsicht: Beim Ausprobieren verschiedener ML-Tools hatte ich damit Probleme. Konkret lief XGboost nur mit multisession!
3
Dieses Statement ermöglicht es, später in der Shell mithilfe von Argumenten die Terminator-Bedingungen zu modulieren.
4
In mlr3 muss man zuerst immer einen Task definieren. Achtung: Man kann ein target definieren, aber keine features.
5
In diesem Schritt wird ein Stratum definiert, nämlich unser target. In der nächsten Zeile wird der Datensatz geteilt (genauer gesagt werden Row-IDs bestimmt) in einen Trainings- und einen Testdatensatz. Der Testdatensatz wird quasi ‘zurückgehalten’, um halbwegs objektiv die zukünftige Prognosegenauigkeit bestimmen zu können. Das ist insbesondere wichtig, wenn wir in Zukunft mit anderen Modellen vergleichen wollen.
6
Hier wird der learner definiert. In unserem Fall ein Random Forest, der mithilfe des ranger packages gefittet werden soll.
7
Wenn man Parameter tunen möchte, dann muss man einen Range angeben in dem der optimale Parameter gesucht werden soll.
8
Hier wird die Art der Kreuzvalidierung festgelegt. In diesem Fall ist es eine 5-fold Cross Validation.
9
Das ist der Tuner und er stammt aus dem mlr3mbo-Package. Wir haben in Punkt 6 den Range der Parameter definiert, aber nicht festgelegt, welche Parameterwerte konkret getestet werden sollen. Dieser Tuner setzt auf Bayesian Optimization und versucht auf Basis der bisherigen Parameterkombinationen die vermutlich beste Kombination für den nächsten Durchlauf zu finden.
10
Der kombinierte Terminator. Denn irgendwann muss auch mal Schluss sein mit dem Machine Learning. Hier wird eine Kombi aus Anzahl der Durchläufe und Dauer genommen. Das ist sehr praktisch, denn man kann einstellen, dass das Ganze z. B. maximal 24 Stunden laufen soll.
11
Hier kommt das eigentliche Highlight: mlr3pipelines! Das wirkt hier jetzt noch unspektakulär. Was macht diese Pipeline? Sie imputiert Missing Values mithilfe eines Regression Trees und macht den Datensatz robust, falls, vor allem beim Splitten der Daten via CV, Unvorhergesehenes auftritt.
Diesen Code packen wir in einen docker Container, schicken ihn auf die Google Cloud um ihn dort ‘laufen zu lassen’! Der konkrete Docker-Container für dieses Projekt sieht so aus:
FROM rocker/r-ver:4.3.1# Systemaktualisierungen und notwendige Linux-PaketeRUNapt-get update &&apt-get install -y\ libcurl4-openssl-dev \ libssl-dev \ libxml2-dev \ libgit2-dev \ git \&&rm-rf /var/lib/apt/lists/*# Installieren von 'pak' von GitHub für die neueste VersionRUNR-e"install.packages('pak', repos = 'https://r-lib.github.io/p/pak/dev/')"RUNR-e"pak::pkg_install('Rdatatable/data.table')"RUNR-e"pak::pkg_install(c('magrittr', 'future','mlr-org/mlr3', 'mlr-org/mlr3tuning', 'mlr-org/mlr3extralearners', 'mlr-org/mlr3learners', 'mlr-org/mlr3pipelines', 'mlr-org/paradox', 'mlr-org/bbotk', 'mlr-org/mlr3mbo', 'mlr-org/mlr3misc', 'mlr-org/mlr3measures','ranger', 'DiceKriging', 'rgenoud', 'forcats', 'future', 'kknn', 'e1071', 'xgboost'))"WORKDIR /tuneCOPY healthcare-dataset-stroke-data.csv /tune/healthcare-dataset-stroke-data.csvCOPY *.R /tune/RUNmkdir /tune/output# Setzen des ENTRYPOINT auf RscriptENTRYPOINT ["Rscript"]
Abbildung 1 zeigt die konkrete Abfolge, wie ich das Docker-Image auf die VM-Instanz von Google übertragen habe. Wichtig ist natürlich, dass man einen Account auf Docker Hub besitzt, um das Image dorthin pushen zu können.
Ebenfalls viel Arbeit spart das konsequente Ausprobieren auf dem eigenen Rechner – das heißt, den Docker-Container lokal (mit wenigen Iterationen) laufen zu lassen, um schnell zu testen.
Um eine VM-Instanz zu starten, probiert man am besten ein wenig herum und wählt eine Maschine, die zum eigenen Problem passt. In der Testphase ist man jedoch relativ limitiert, das heißt, man kann nicht beliebig große Instanzen mieten. Entsprechend sollten die zu lösenden Machine-Learning-Probleme nicht zu groß sein!
Abbildung 1: Verteilung der einzelnen auc Werte je Parameterkombination
Die Ergebnisse (Random Forest)
Am Ende des Tages wollen wir irgendetwas über die Daten erfahren.
Welche Variablen sind wichtig?
Wie ist der funktionale Zusammenhang der Variablen mit stroke?
Wie genau können wir vorhersagen?
Wie müssen die Parameter gewählt werden um möglichst genaue Vorhersagen zu treffen?
Parameter
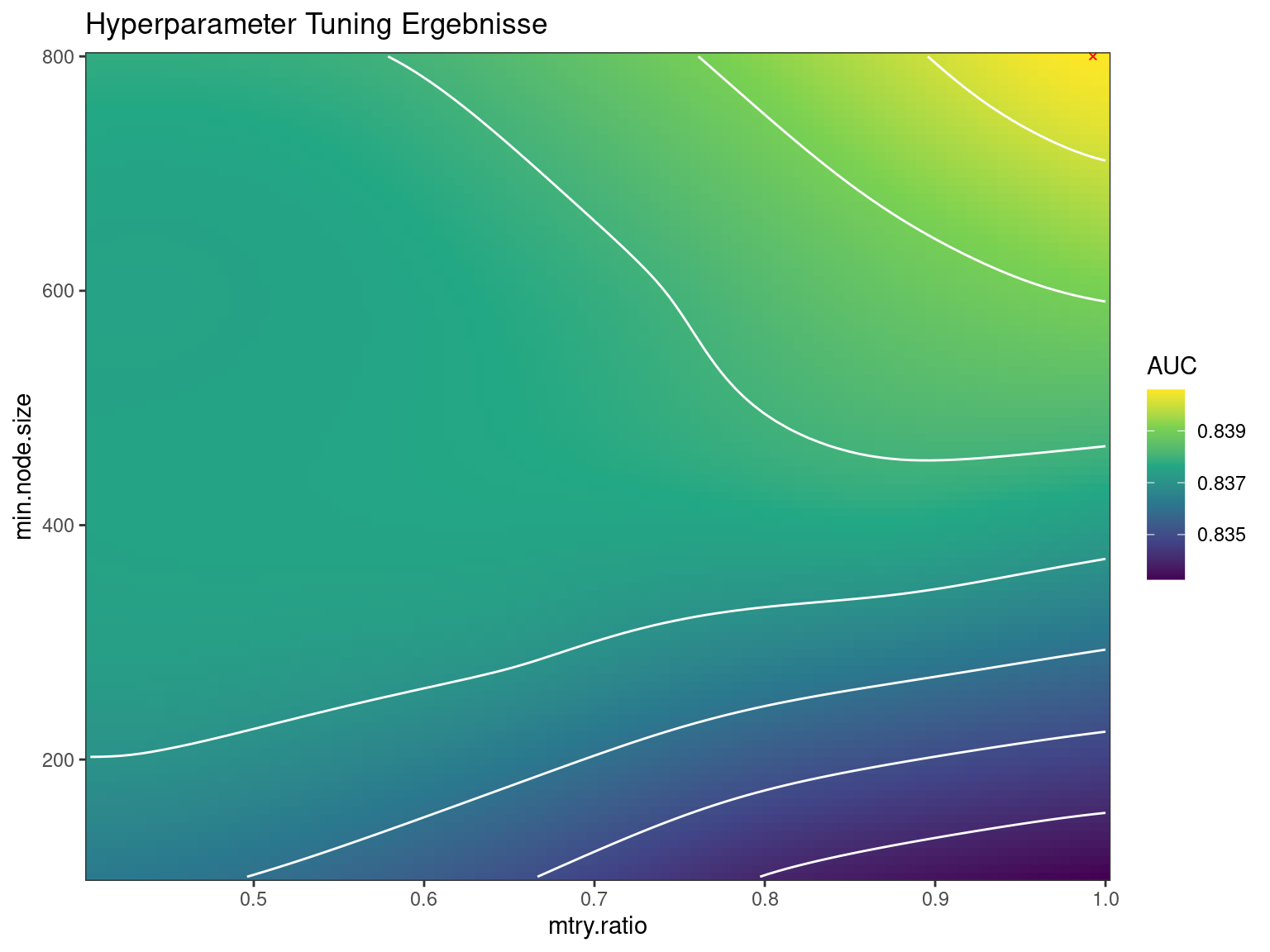
Wir haben das Modell mittels Bayesian Optimization getuned. Das heisst, es wird nicht per Zufall, oder deterministisch (via grid) gesucht, sondern es wird dort gesucht wo auf Basis der vorliegenden Daten ein möglichst hoher auc vermutet wird – das ist die Fläche unter eine ROC Kurve. Je größer die Fläche desto besser. Schauen wir uns also die Parameterkombination an, um zu sehen wo sich ein Maximum einstellt.
Wir haben 2 Parameter getunded:
min.node.size: Ist die minimal notwendige Anzahl bei der ein Node gerade noch gesplittet werden darf. D. h. es wird auch Nodes geben mit einem geringeren N als min.node.size – diese können aber nicht mehr gesplittet werden!
mtry.ratio: Anteil, wieviele Variablen genutzt werden sollen.
Abbildung 2 zeigt die Verteilung des auc je nach Parameterkombination. Mit einem roten X ist die Parameterkombination mit dem höchsten auc gekennzeichnet. Diese liegt am Rande unseres Parameterraums. Betrachtet man den kompletten Raum wirkt es so, dass eigentlich alle Kombinationen zu recht guten Ergebnissen führen. Der gelbe Fleck am Rand suggeriert, dass eventuell noch bessere Ergebnisse zu finden wären, wenn wir min.node.size noch weiter nach oben schrauben würden.
Abbildung 2: Verteilung der einzelnen auc Werte je Parameterkombination
Hier klicken um das Tuning Ergebnis des Random Search zu sehen
Wer sich dafür interessiert: Ich habe das Ganze nochmal als “Random Search” durchlaufen lassen. Der Nachteil: Es wird viel unsystematischer gesucht, d. h. der Algorithmus sucht auch in Ecken wo er ziemlich sicher weiß, dass kein besserer auc Wert zu erzielen ist. Der Vorteil: Er sammelt überall vertreut Daten. Gleichzeitig hab ich min.node.size auf 1200 erhöht. Abbildung 3 zeigt das Ergebnis. Es ist gut zu erkennen, dass das Maximum in einem sehr ähnlichen Bereich gefunden wird, wie zuvor das Tuning mittels mlr3mbo.
Abbildung 3: Verteilung der einzelnen auc Werte je Parameterkombination
Variable Importance
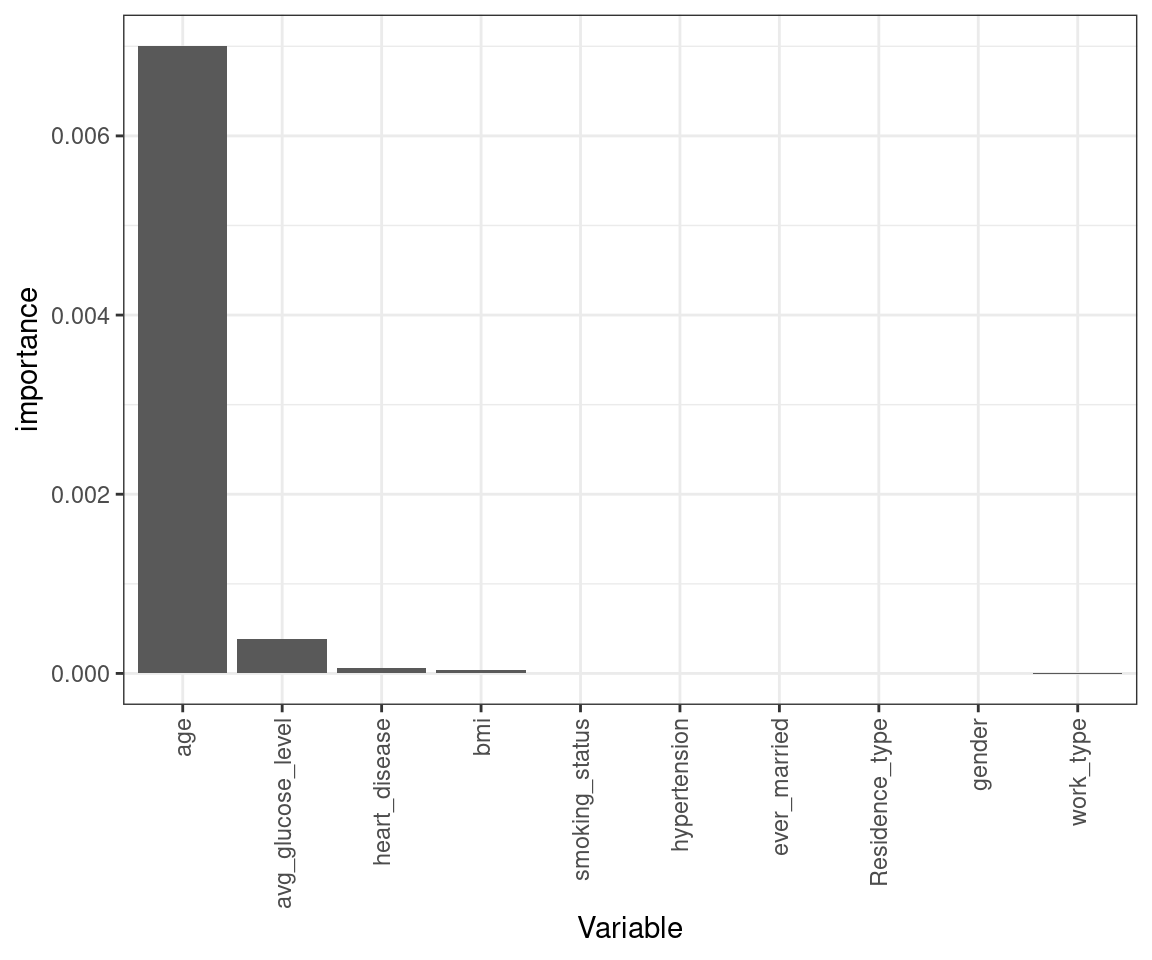
Die Variable Importance gibt an, welche Variablen am wichtigsten für die Vorhersage sind. Das Package ranger, auf das hier zurückgegriffen wurde, um die Random Forests laufen zu lassen, berechnet unter anderem die ‘Permutation’-Variable-Importance. Dabei wird für jeden Tree dessen Accuracy anhand des OOB-Samples bestimmt, um dann im nächsten Schritt jeweils eine Variable zufällig zu permutieren, damit der Rückgang der Accuracy gemessen werden kann. Je stärker dieser Rückgang ausfällt, desto ‘wichtiger’ ist die Variable. Offensichtlich ist die Variable age besonders wichtig. Inhaltlich hätte ich eher mit der Variable heart disease gerechnet – umso interessanter, dass age so deutlich dominiert. Vermultlich weil auch vergleichsweise junge Personen im Datensatz sind, bei denen Schlaganfälle so gut wie nicht vorkommen (siehe Tabelle 1).
Abbildung 4: Variable Importance
Funktionale Zusammenhänge
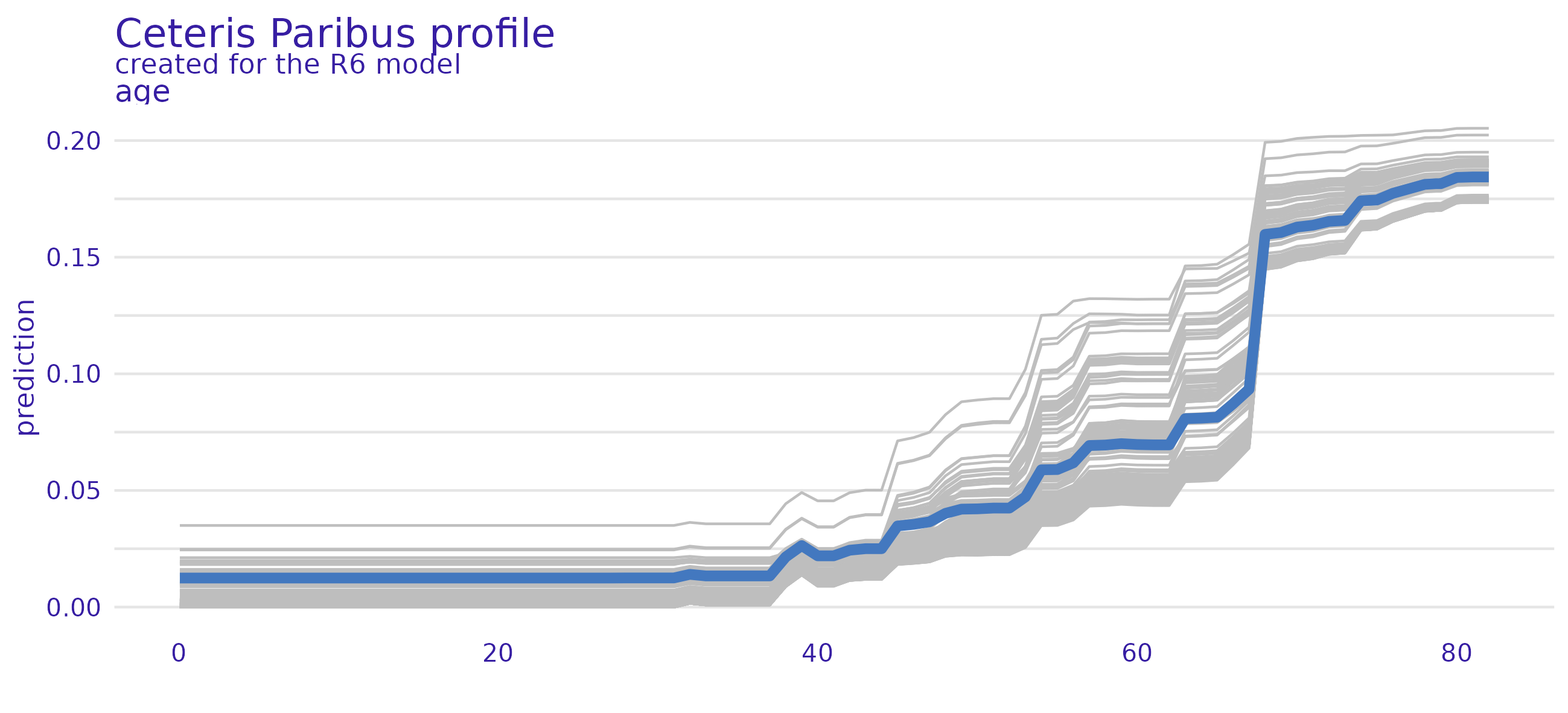
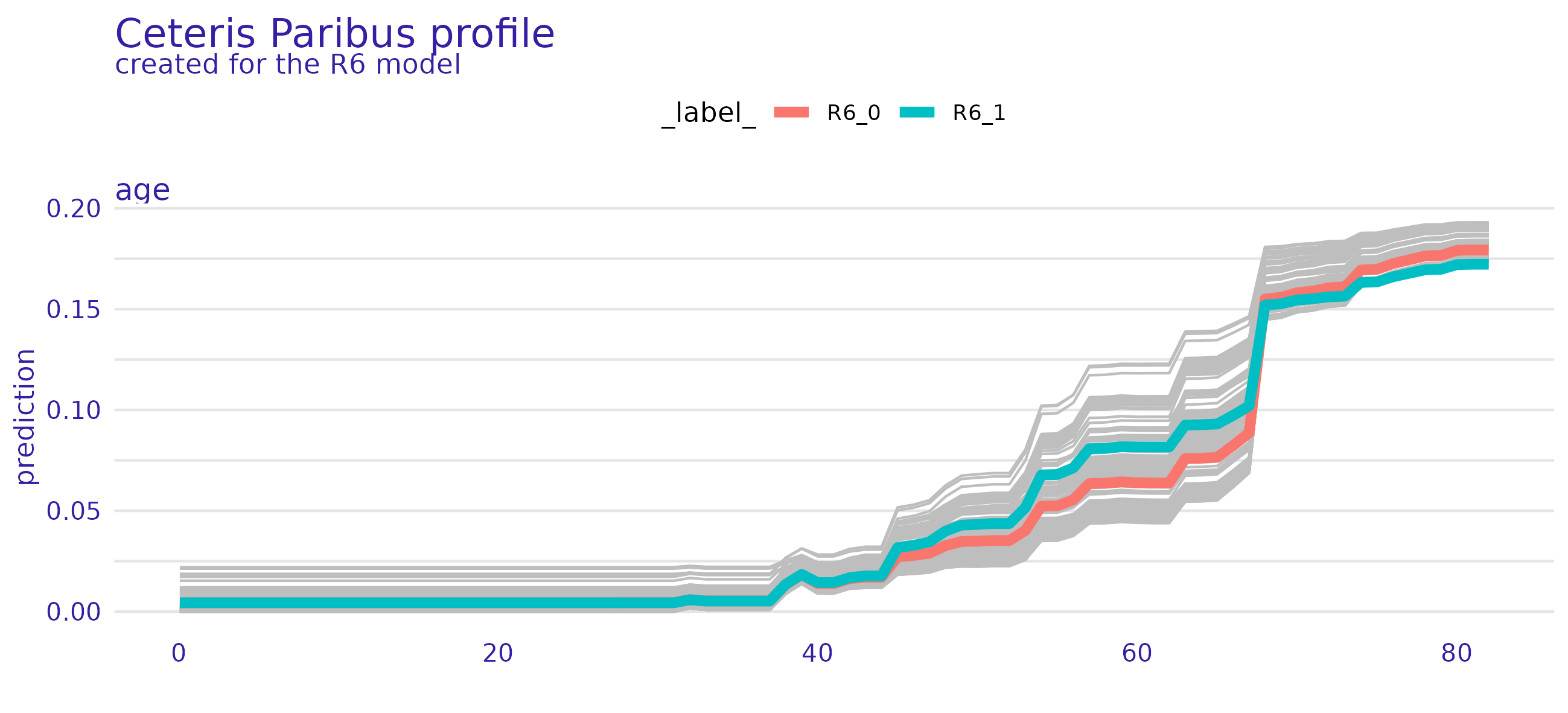
Wenn man nicht nur einem einzelnen Wert vertrauen will, sondern sich auch die Erklärungskraft jeder einzelnen Variable und deren funktionalen Zusammenhang ansehen möchte, kann mittels DALEX und DALEXtra package ansprechende ‘Partial Dependene Plots’ anfertigen1! In Abbildung 5 sieht man den Zusammenhang der Variable age mit der Wahrscheinlichkeit einen stroke zu erleiden. Wie zu erwarten war: je älter desto eher droht die Gefahr eines Schlaganfalls. Dass das Vorliegen einer heart disease sich auch förderlich auf einen Schlaganfall auswirkt zeigt Abbildung 6.
Abbildung 5: Partial-Dependence Plot der Variable Alter
Abbildung 6: Partial-Dependence Plot der Variable Alter zusammen mit Heart disease
Das kann man natürlich für alle Variablen machen und diese miteinander kombinieren. Wir wollen uns hier keinesfalls im Inhaltlichen verlieren. Bezüglich Prognose stellt sich noch die Frage, was wir in Zukunft erwarten können? Wie gut wird das Modell performen, wenn wir es auf unseren bis jetzt zurückgehaltenen Testdatensatz anwenden?
Testdatensatz
Irl macht man so eine Prozedur wie diese ja dafür, um am Ende des Tages ein Modell zu haben, um zukünftige Fälle klassifizieren zu können, oder zukünftigen Personen eine stroke Wahrscheinlichkeit zuzuweisen. D. h. wir wollen jetzt abschätzen, wie gut wir unbekannte Datensätze vorhersagen würden. Diese Info bekommen wir, indem wir unser getuntes Modell, auf den Testdatensatz anwenden.
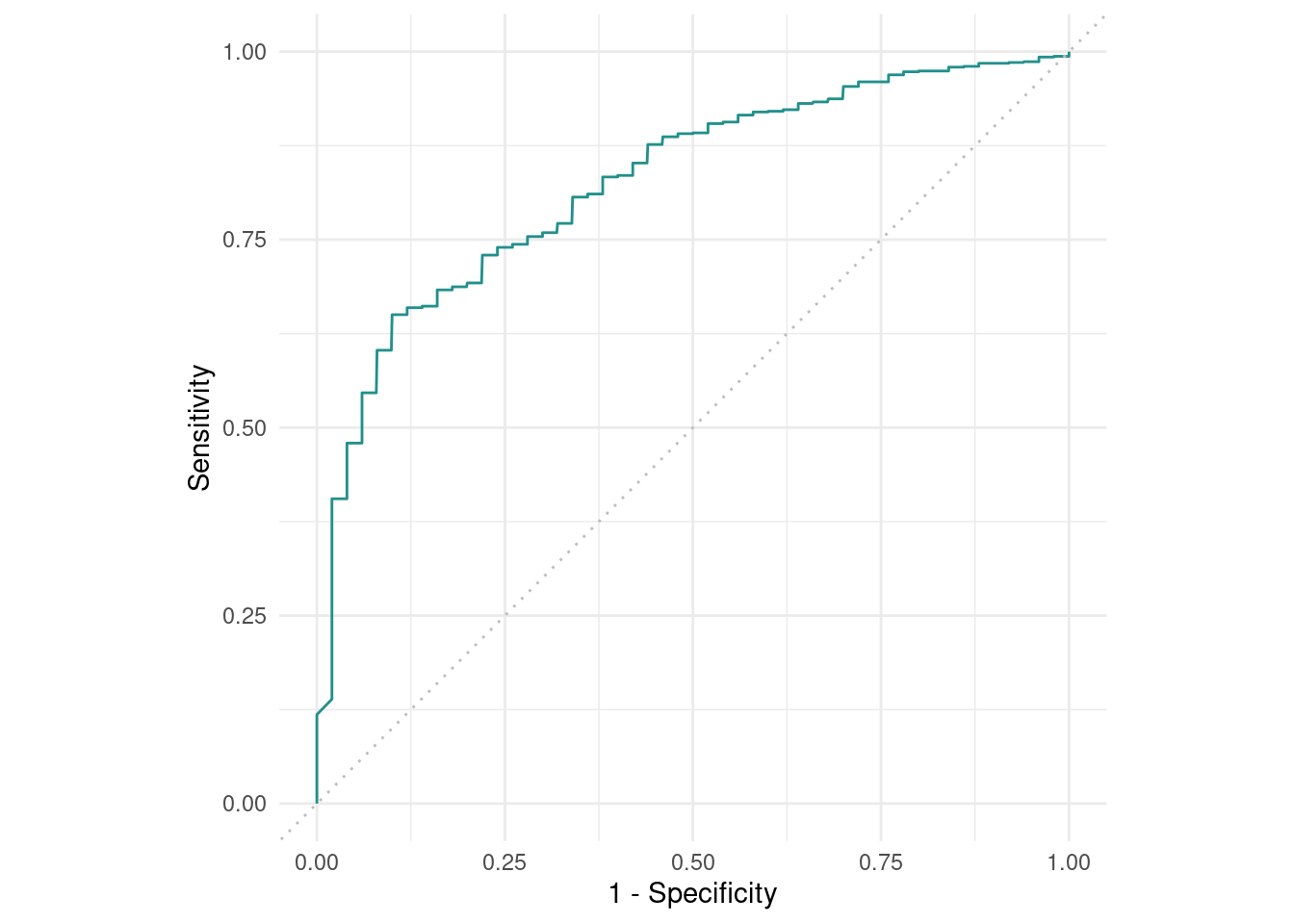
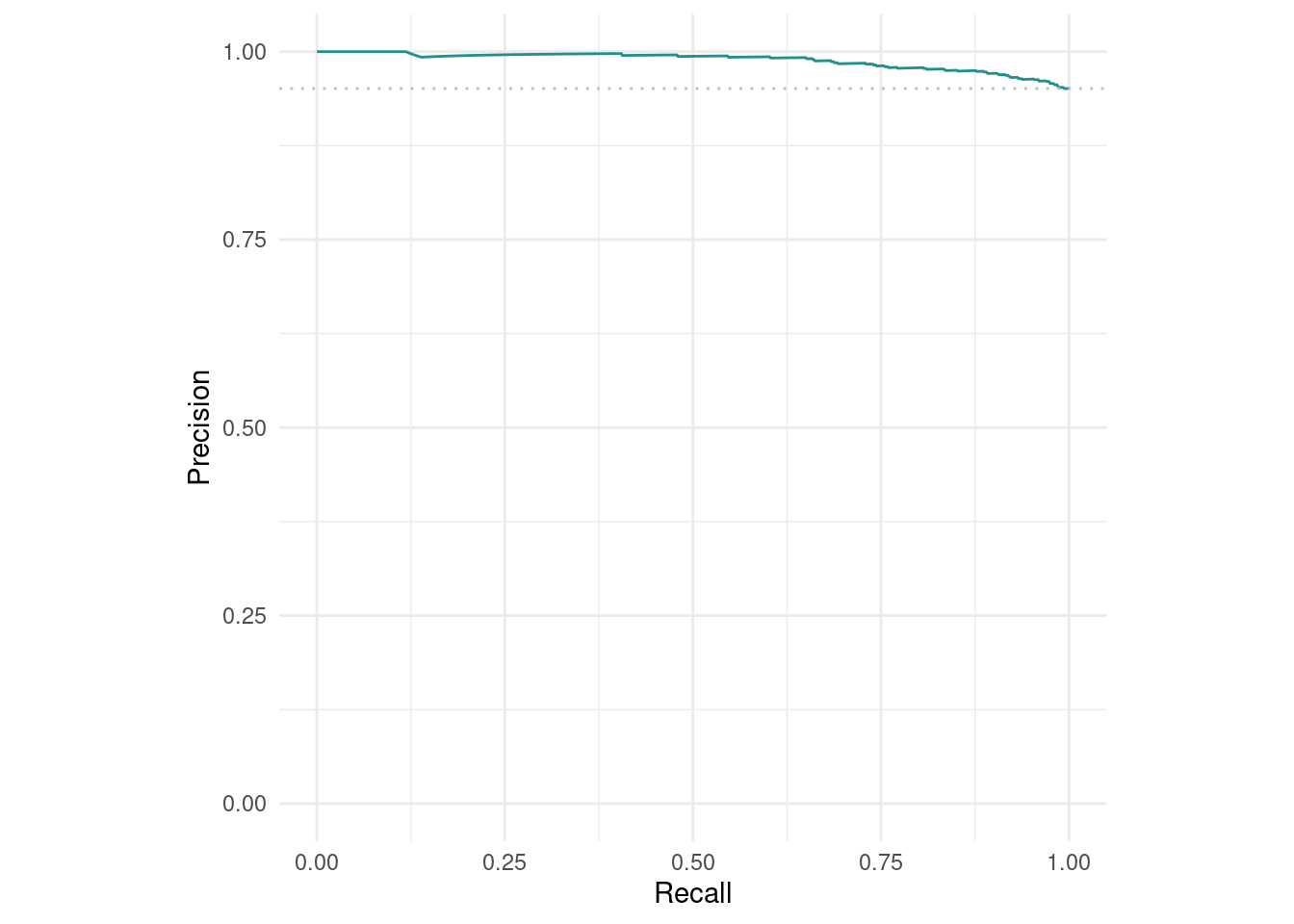
Abbildung 7 und Abbildung 8 zeigen die Modellperformance des Modells auf den Testdaten. Was wäre ideal? Die ideale ROC Kurve steigt extrem steil (möglichst senkrecht) an und verläuft anschließend am oberen Rand möglichst parallel zur x-Achse. Umgekehrt verhält es sich mit dem PR-Plot. Er sollte von Anfang an oben verlaufen und möglichst spät steil abstürzen; in einer idealen Welt. Beide Plots berechnen für viele unterschiedliche Thresholds die jeweiligen Kennwerte (Specificity, Sensitivity etc.) aus und stellt diese als Gesamtgrafik dar.
Unser Modell schaut nicht so schlecht aus. Allerdings ist auch noch Luft nach oben; hoffentlich.
Abbildung 7: ROC Kurve auf den Testdaten
Abbildung 8: PR Kurve auf den Testdaten
In einem weiteren Blogbeitrag, wird dieser Datensatz noch weiter durch den Daten Fleischwolf gedreht. Es wird sich die Gelegenheit ergeben, das neue Modell anhand des Testdatensatzes mit diesem Random Forest zu vergleichen.
Fußnoten
Hier sind es eigentlich ‘Accumulated Local Dependence’ Plots.↩︎